Cluster 02
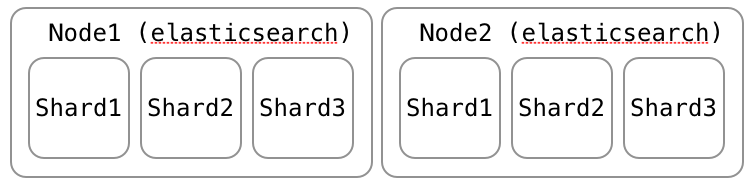
- node: elasticsearchインスタンス、ふつう1サーバ
- shard: 分割されたデータを持つ、Luceneインスタンス
- replica: shardの複製、フェイルオーバーとパフォーマンス
2012 11/18 tokyo nodefest 2012 @swdyh
2012 11/18 tokyo nodefest 2012 @swdyh
今日のスライド http://swdyh.github.com
% curl -X PUT localhost:9200/demo-index% curl -X PUT localhost:9200/demo-index/x/1 -d '{"text": "hello world" }'% curl localhost:9200/demo-index/x/_search -d '{ "query": { "text": { "text": "hello" } } }'
文章に区切りがないのでそれをなんとかする必要がある
mappingsでanalyzerにkuromojiを指定
bin/plugin -install elasticsearch/elasticsearch -analysis-kuromoji/1.0.0
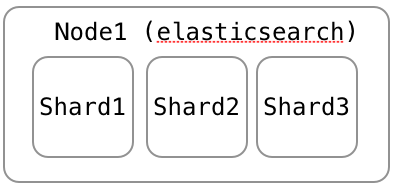
3 shards 1 replica: 1 nodeの場合、replicaはできない
3 shards 1 replica: nodeを追加、replicaが作成される
3 shards 1 replica: さらにnodeを追加、shardがリバランスされる
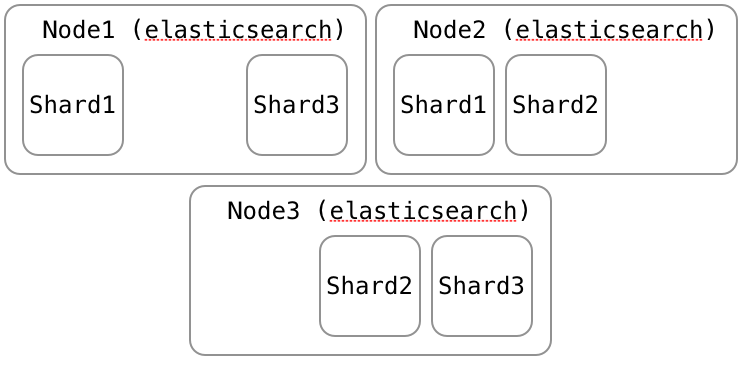
3 shards 1 replica: node3が落ちると、2nodeのときのようになる
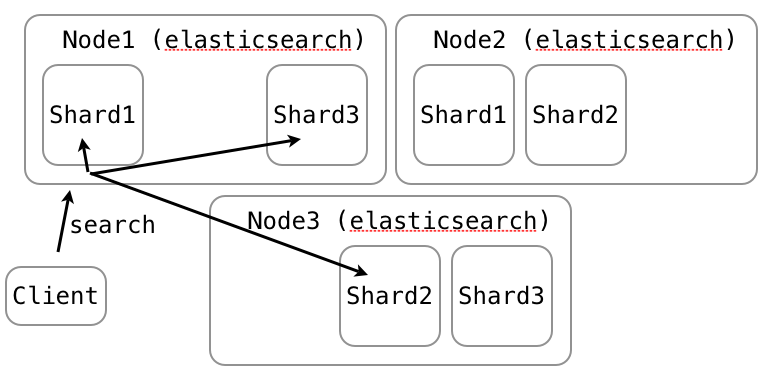
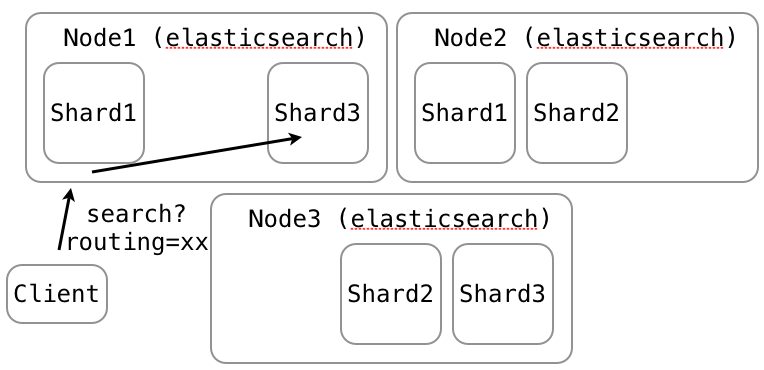
curl -X PUT localhost:9200/demo-index\/x/1?routing=201211 -d ...curl localhost:9200/demo-index\/x/_search?routing=201211 -d ...
var request = require('request')request.put({uri: 'http://localhost:9200/demo-index',json: true}, function(err, res, val) {console.log(err, val)})
request.put({uri: 'http://localhost:9200/demo-index',json: { mappings: { demo: {properties: { text: { type: 'string',analyzer: 'kuromoji' } } } } }}, function(err, res, val) {console.log(err, val)})
request.put({uri: 'http://localhost:9200/demo-index/demo/1',json: { text: 'こんにちは世界' }}, function(err, res, val) {console.log(err, val)})
// idが自動で付加されるrequest.post({uri: 'http://localhost:9200/demo-index/demo',json: { text: 'こんにちは世界' }}, function(err, res, val) {console.log(err, val)})
request({uri: 'http://localhost:9200/demo-index/demo/_search',json: {query: { text: { text: '世界' } }}}, function(err, res, val) {console.log(err, val)})
Yet Another npm Search: elasticsearchとNode.jsでつくったnpm検索
http://ya-npm-search.herokuapp.com/